

The Shifting Investment Sands of the AI Infrastructure Thematic: From Training to Inference
Identifying the Next Supply Chain Bottlenecks in AI Data Center Infrastructure


The following report is a thematic industry and supply chain investigation generated by The Inferential Investor’s professional research prompt of the same name.
While the AI Infrastructure investment theme is getting long in the tooth, we are posting this as it contains fascinating insights on the impact of the shift from AI model training to more everyday inference requirements, that potentially have far reaching investment implications. The future for past winners such as NVIDIA may not be as rosy while old industrial names with large operations in Large Power Transformers and other components may see better demand and a return of pricing power.
Some interesting names are identified. Some have run hard already while others have not. What this report tells us is that the investment landscape we have seen in the last two - three years will be very different to the landscape of the next.
Disclaimer: Readers are directed to refer to the disclaimer at the end of the report. No mention of any stock in this report is a recommendation to buy, sell or hold. This is for educational purposes only and is not financial advice. The report is generated by AI and can contain errors.
Executive Summary: The Coming Transition from Training to Inference
The primary investment opportunity in Artificial Intelligence (AI) infrastructure is undergoing a fundamental transition. After a multi-year cycle dominated by advancements in computational logic, the most acute and durable supply chain bottlenecks are now cascading into the physical infrastructure required to power, cool, and connect these advanced systems. The industry-wide pivot from the initial, capital-intensive phase of model training to the mass-scale, operational phase of inference is the catalyst for this shift. This report identifies three critical areas poised for multi-year supply/demand imbalances and significant investment opportunities: (1) High-Voltage Power Infrastructure, (2) Advanced Liquid Cooling Components, and (3) High-Speed Optical Networking.
The nature of AI workloads is changing. Training large models is a periodic, throughput-intensive task. Inference, the application of these models to generate real-world outputs, is a continuous, latency-sensitive process that scales directly with user adoption.1 This shift from a centralized, batch-oriented workload to a distributed, real-time demand profile fundamentally alters the engineering and supply chain requirements for the data centers of the next decade.
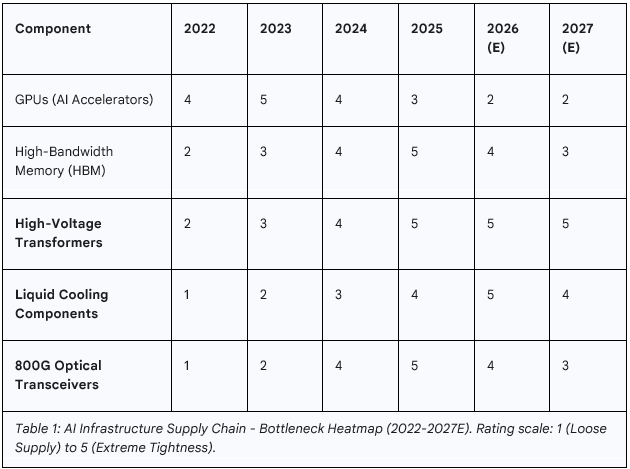
Our analysis points to a clear investment roadmap tracking this cascading bottleneck:
● 2022-2024 (The Training Era): This period was defined by the scarcity of high-performance Graphics Processing Units (GPUs) necessary for training foundational models. NVIDIA was the principal beneficiary, capturing immense value as the critical enabler of the generative AI boom.4
● 2025/6 (The Memory Wall): As inference workloads began to scale, the demand for memory bandwidth and capacity intensified. This created a bottleneck in High-Bandwidth Memory (HBM) and advanced DRAM, shifting market leadership and investor returns toward memory suppliers who are now aggressively expanding capacity to meet this demand.5
● 2026 and Beyond (The Physics Era): Looking forward, the constraints are no longer just about silicon. The bottlenecks are cascading to the physical limits of power delivery, heat dissipation, and data transmission. The most significant alpha generation opportunities will be found not in the logic layer, but in the suppliers of previously overlooked, mission-critical physical infrastructure.
The following table provides a visual summary of this thesis, mapping the assessed intensity of supply chain tightness across key AI infrastructure components over time.
Section 1: The Great Workload Shift: From Training Dominance to Inference at Scale
The entire investment landscape for AI infrastructure is being reshaped by a fundamental change in how AI models are utilized. The initial phase, focused on creating large models, is giving way to a new era defined by their widespread application. Understanding the distinct characteristics of these two workload types—training and inference—is critical to identifying where future supply chain pressures will materialize.
1.1. Defining the Dichotomy: Training vs. Inference
AI Training is the process of teaching a model by feeding it vast datasets. This phase is characterized by its immense computational requirements and is optimized for maximum data throughput. Training workloads are computationally heavy, involving complex calculations like backpropagation that run iteratively for days or even weeks across massive clusters of thousands of GPUs.1 Because this process occurs offline, it can tolerate higher latency. The cost of training is a significant, but largely one-time or periodic, capital expenditure associated with model development or updates.1
AI Inference, in contrast, is the process of using a trained model to make predictions on new, real-world data. Each individual inference query is computationally lighter than a training run, but it happens continuously and in real-time.1 For applications like chatbots, fraud detection, or autonomous systems, responses must be delivered in milliseconds, making low latency a paramount concern.1 The cost of inference is operational and ongoing, scaling with every user request. Over a model’s lifecycle, the cumulative cost of performing billions of inferences can far exceed the initial training cost, making efficiency—often measured in “tokens per second per dollar”—the primary optimization target.1
1.2. Architectural Implications for Data Centers
The differing demands of training and inference necessitate distinct data center architectures. The training era gave rise to the “AI Factory” model: massive, centralized campuses housing tens of thousands of tightly interconnected GPUs designed for a single, monolithic task.10
The inference era requires a more distributed and flexible infrastructure. While large cloud data centers will continue to host a significant portion of inference workloads, the need for low latency is driving compute closer to end-users, fueling the growth of edge computing and influencing the design of regional data centers.2 Furthermore, inference traffic is often described as “spiky” and volatile, with unpredictable bursts of user requests.11 This demands an infrastructure built for horizontal elasticity, with sophisticated load-aware routing and dynamic scaling capabilities, placing new and intense pressures on network and power management systems that were not primary considerations in the training-centric model.11
1.3. Quantifying the Shift: A Market in Transition
Market forecasts confirm this transition is well underway. The global AI Inference Market is projected to grow from USD 106.15 billion in 2025 to USD 254.98 billion by 2030, representing a compound annual growth rate (CAGR) of 19.2%.15 This signals a massive buildout of inference-specific hardware and infrastructure. Market analysis from IDC confirms that while training drove the initial investment wave, inference is now fundamentally shifting the overall spending pattern, and is expected to account for a larger share of total compute and semiconductor consumption from 2025 onward.16
This workload shift also explains a key market paradox: the flatlining of GPU prices in 2025 despite continued strong demand for AI compute. The highest-margin, most powerful GPUs (e.g., NVIDIA’s H-series and B-series) are essential for the computationally intensive task of training. Inference, however, can be run efficiently on a wider array of hardware. This includes not only top-tier GPUs but also previous-generation models, lower-power accelerators, and increasingly, custom-designed ASICs like Microsoft’s “Maia” and Google’s TPUs, which are optimized for cost-effective model serving.5 As the market’s workload mix shifts from nearly 100% cutting-edge training to a blend of training and inference, the blended average selling price (ASP) and margin profile for the broader “AI accelerator” market naturally moderates. This dynamic validates the observation of slowing returns for pure-play compute vendors and reinforces the strategic imperative to identify the next, less-mature bottlenecks in the supply chain.
Section 2: The Maturing Bottlenecks: Compute and Memory
The investment themes that dominated the 2022-2025 period—GPU compute and high-bandwidth memory—are now maturing. While demand remains strong, the supply chains are responding, and competitive dynamics are normalizing. This normalization is precisely why the search for new, more acute bottlenecks is now a priority.
