

Hallucinations Happen. Here’s How Investors Can Keep AI Honest.
Minimizing Hallucination Risk in Investment Research Workflows


The following post is part of our Best Practice AI Investment Research series that teaches both individual investors and professionals buy- and sell-siders how to employ AI seamlessly into your fundamental process driven investment workflows. Other primers can be found under the Techniques tab of our Substack site.
Subscribe for free to keep up to date with best practice AI integration in investment settings:
Introduction — Getting on top of hallucinations
AI can tear through filings in seconds, but even the most recent AI models sometimes speak with confidence where evidence is thin. In investment research, that’s a risk. The good news: while hallucinations are inevitable when models wrestle with sprawling, cross-referenced sources, simple, thoughtful techniques can push error rates down to levels you can govern.
This article lays out what hallucinations are, why they show up in financial work, what recent research finds about failure modes and fixes, and how to build an ingest-and-preprocessing front end that gives models fewer chances to wander. Throughout, we point to tactics we use at The Inferential Investor to keep answers anchored to primary sources.
What hallucinations are and why they occur
In plain language, a hallucination is a confident answer that’s not supported by the source. In finance, that usually means a number, date, policy, or interpretation that doesn’t appear in the filing you’re analyzing. Research teams building finance-specific evaluations report that models often deliver polished, seemingly well-justified responses that are still wrong especially on questions that require calculations or multi-passage reasoning across a dense filing.
Why this happens in investment work:
Guessing beats abstention in many training and evaluation setups. Benchmarks often treat a refusal to answer as “wrong,” nudging models toward taking a swing rather than asking for more evidence. In finance, that’s upside down; abstention is often safer than a confident miss. OpenAI’s September 2025 paper “Why Language Models Hallucinate” argues this point. Training and evaluation regimes often reward confident guessing over calibrated uncertainty. That is, incentives drive the behavior. OpenAI CDN
Errors compound with length. Generating long, explanatory text is a token-by-token autoregressive process. Small errors in one early token can snowball into persuasive but error-prone paragraphs if the model isn’t pinned to citations.
Training cut-offs and domain shift. Filings change over time. For example, accounting policies and segment definitions differ by issuer and year. FinanceBench’s authors underline that models need up-to-date, issuer-specific knowledge, numerical reasoning, and the ability to blend structured tables with narratives - skills that general pretraining doesn’t guarantee.
Tables, units, and arithmetic are brittle. Handling “USD in millions,” reconciling cash flow bridges, and joining notes to statements is substantially harder than quoting a paragraph. The FinanceBench team explicitly flags numeric reasoning and multi-source joins as core challenges.
The takeaway: hallucinations are a part of using AI models. The same transformer architecture and training processes that allow the models to understand context and answer questions are autoregressive and probability based and consequently still “fill in the blanks” when uncertainty is high. However there are many steps that can be taken to minimize hallucinations to a level they are a minor inconvenience that is far outweighed by the productivity boost of AI.
The Hughes Hallucination Evaluation Model (HHEM) Leaderboard reports general (non domain specific) hallucination propensity for each AI model and reveals some notable trends. First, Gemini and ChatGPT’s models outperform other models in this respect. HHEM reports surprisingly poor performance for Claude’s models such as 3.5 Sonnet (8-9x higher propensity than Gemini 2.5) however successive model releases are closing the gap (3.7 Sonnet reduced this to 4.4% propensity vs 1.1% for Gemini 2.5 Pro. Meta’s Llama , while also improving over successive releases still has a large gap to close relative to OpenAI and Google. Of the latest model variants from the major players, Gemini 2.5 PRO comes out on top at 1.1% with GPT-5 at 1.4%. Gemini’s encoder / decoder architecture, that can attend to the entire context window at the same time, is obviously superior in this respect to a fully autoregressive decoder-only model (ChatGPT).
Answer length does increase hallucinations. Some studies report that constraining models to a simple yes/no answer can get accuracy to 100%. The “wordier” the models, the more they hallucinate. The following chart shows this from the HHEM data. Each dot represents a different model comparing their average words in a news summary response to their hallucination propensity:
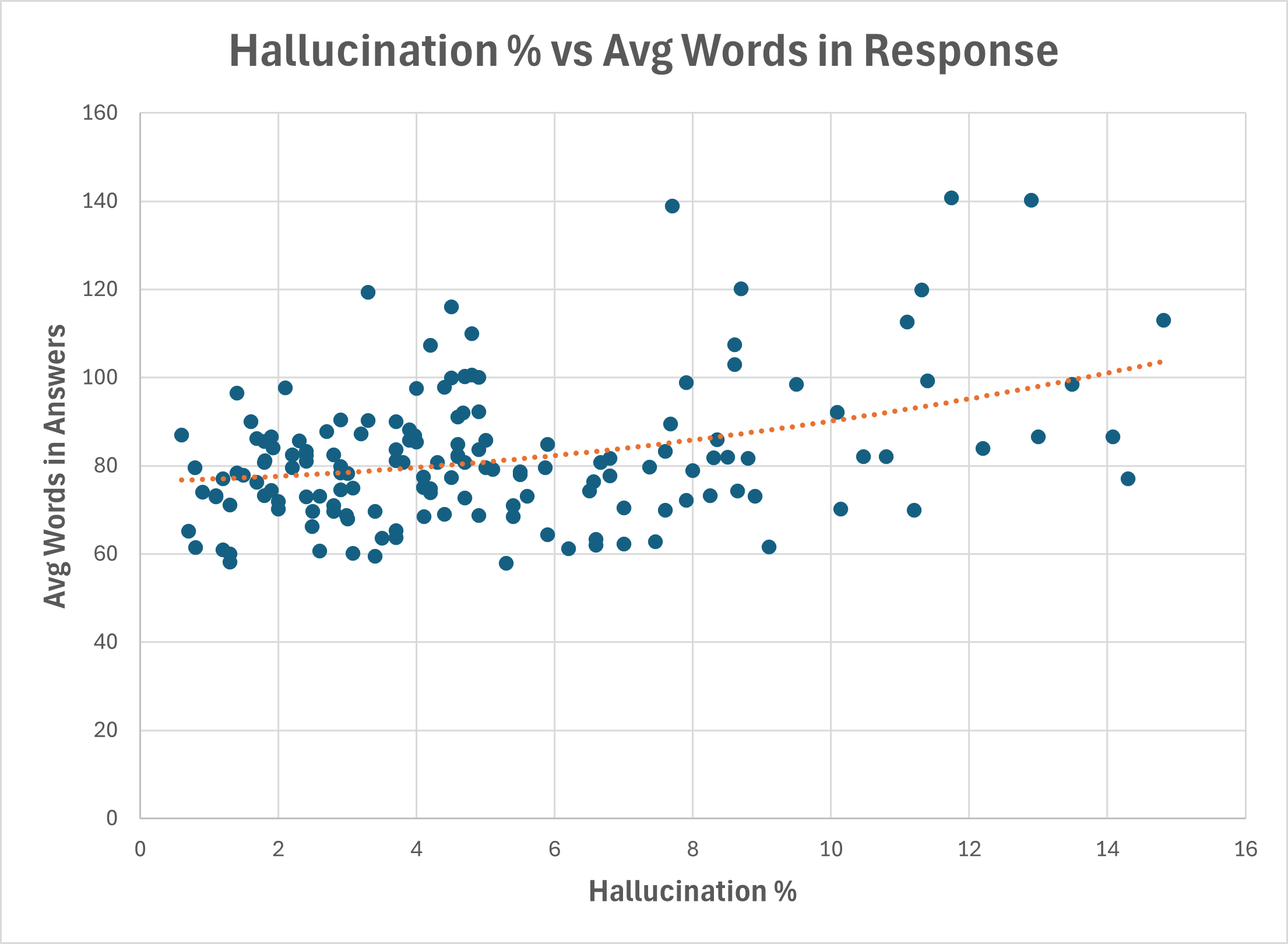
source: HHEM data, The Inferential Investor analysis
This demonstrates that constraining a model to shorter answers can reduce hallucinations. Small reductions in words, produce large reductions in hallucinations, at least as far as the data shows across models
Complex financial information that raises the risk
Some investor questions are magnets for hallucinations due to the complexity and density of financial documents. If you take a company 10-K, the model has to deal with 150 pages of structured and unstructured data where formats, units, currency and subtle definitional changes all happen from section to section. Based on published findings and hands-on evaluation, these categories are higher-risk. That doesnt mean the model will get it wrong. Most of the time, I find Gemini and ChatGPT perform very well, however across an entire 30-40 page deep dive report I usually find one or two corrections required.
Cross-statement reconciliations. “Walk me from net income to cash from operations,” or “square this balance-sheet movement with the cash flow statement.” These require multi-page and multi-table joins and unit discipline which are common failure points highlighted in FinanceBench’s breakdown of “metrics-generated” questions.
Units, scaling, and per-share conversions. A header that reads “USD in thousands” vs “millions” can trip up a model when units change table to table. The benchmark study permits small rounding differences, but documents many outright magnitude errors when models calculate across statements.
Footnote policy nuance. Whether revenue is recognized over time or at a point in time; how contract liabilities move; lease discount rates; short-term lease expedients; market-based RSUs with Monte Carlo valuation - these subtleties live in Notes, not in headlines. Retrieval has to pull the correct policy span, not a generic explanation.
Capital structure and dilution. Bridges from basic to diluted, anti-dilutive exclusions, and instrument-specific rules trip models that try to generalize from memory rather than cite the EPS note.
Debt ladders and covenants. Maturities, variable-rate exposure, and covenant headroom are often scattered across multiple notes and Item 7A. Misalignment across sections is a frequent source of high-confidence mistakes.
Prices and time series. A finance-specific hallucination study shows why closed-book (no RAG to websites or other sources) price questions are a dead end. As a rule - NEVER ask a model for a timeseries of prices from memory unless you are willing to cross check every single data point. The model likely will make up the answer. Tool-calling is the remedy (near-zero accuracy without a tool vs. near-perfect when a function call fetches the price).
What the research says about hallucination risk in filings and finance data
Two complementary studies offer practical guidance.
FinanceBench: the “what investors actually ask” evaluation
FinanceBench is a large benchmark built on real questions over public filings, with a 150-case human-review set used to compare model configurations. The topline is sobering but useful:
Closed-book is a non-starter. Without access to filings, GPT-4-Turbo answered only 9% correctly; 88% were refusals in this setup. This is not really surprising. We always advocate attaching the source document to your task request as a minimum and to consider pre-processing as described later in this post.
Retrieval helps, but width of scope also matters. A single-document vector store for the target filing materially outperformed a shared store indexing all filings (GPT-4-Turbo 50% vs 19% correct in the human-review set). Ie if the documents are long and complex attend to one at a time.
Long-context is powerful but imperfect. Stuffing the filing directly into the prompt yielded 79% correct for GPT-4-Turbo (Claude-2: 76%), yet incorrect answers still exceeded refusals—a sign that when models err here, they tend to hallucinate rather than abstain.
“Oracle” shows the ceiling. Handing the model the exact evidence pages for the specific question (the oracle technique) produced 85% correct for GPT-4-Turbo which is evidence that retrieval is often the bottleneck, not generation. GPT-5 is likely even higher now.
Prompt order matters. Presenting evidence before the question (“context-first”) significantly beat “context-last” in long-context settings—78% vs 25% for GPT-4-Turbo in the ablation study. This is due to the autoregressive structure of many models (Gemini can be different due to encode-decoder architecture).
Where models struggle most. Performance is weakest on metrics generation questions that require numeric reasoning and multi-passage retrieval
In short: retrieval quality, source discipline, and prompt order are decisive. Even with long context stuffing, verification still matters.
Finance hallucination study: task-level fixes
A second paper, Deficiency of LLMs in Finance: An Empirical Examination of Hallucination, probes acronyms, long-form terminology explanations, and stock-price lookups—then tests mitigations:
RAG lifted factuality on obscure finance terms and acronym expansions vs. from-memory generation.
Tool-calling for prices transformed performance: near-zero accuracy without tools versus correct when the model produced the expected function call for a data API.
Few-shot and DoLa (a decoding tweak) added incremental gains in specific pockets, but neither replaced the need for grounding and tools.
These results square with FinanceBench: retrieval and tools confront the cause of hallucinations in finance (missing or misused evidence), while pure prompting tweaks address the symptoms.
Best practice hallucination management - Start with ingest & preprocessing of complex documents
If you’re building an AI workflow for research, treat ingest & pre-processing of long, complex source documents as your default.
After hundreds of hours working with sophisticated prompts applied to complex documents such as 10-Ks and experiencing the range of problems that can occur, I’ve developed a prompt set to ingest, verify and cross reference information within 10-K’s and 10-Qs to minimize hallucination risk. This will be accessible for copy/paste from our prompt library. The investor runs the pre-processing prompt with an attached filing prior to running the research task prompt.
This step extracts and retains the structure of the document (“markdown”) that is often lost by the models, particularly in PDFs, appends metadata to every datapoint or “chunk” (ticker, period, page etc) to reduce the liklihood of the model confusing and conflating data points with its memory, improves cross-statement data joining and calculations and so on. The following principles are applied in this pre-processing prompt based on the research studies:
A. Setting the rules of the game
Scope discipline. Index one document at a time for deep work (e.g., the target 10-K). Only widen scope on explicit instruction. FinanceBench shows why: shared stores invite cross-issuer contamination and tank accuracy.
No citation → no claim. Require span-level citations with page anchors on every datum. In research audits, this single rule changes behavior—models learn to look first.
Abstention is allowed. Reward “Not determinable from the cited text” over confident invention. The benchmark’s qualitative analysis argues this is safer than an incorrect answer presented with clean math.
B. Ingesting that respects accounting structure
Prefer HTML/XBRL; otherwise parse PDF carefully. Preserve a Markdown outline of the report (Items and Notes). Extract tables as tables with row/column headers.
Chunk with strategic intent.
Narrative: 500–1,200 tokens, 10–15% overlap; split on headings/paragraphs.
Tables: never split rows/columns.
Notes: keep intact where possible; otherwise, split by sub-headings (e.g., “Contract balances,” “Maturities,” “Covenants”).
Attach metadata to every chunk:
{ticker, cik, filing_type, fiscal_year, period_end, currency_declared, units_declared, page_range, section_type, note_id, source_url}. This makes it easy to filter by issuer, period, or section and prevents wrong-document bleed-through—one of FinanceBench’s central findings.Normalize units with a visible trail. If a table says “USD in millions,” store the multiplier and emit both stated and normalized values. Under each rendered table, print: “Units: USD in millions (×1,000,000).”
Build a Notes directory with cross-refs. Index each note’s title, page span, and expected fields (e.g., Note 7—Debt: maturities by year; weighted avg rate; covenants), then link line items from statements to their note. This shortens the path from “interest expense” to the covenant discussion in the back pages.
C. Retrieval, prompting and verification that reduce guessing / simplify checks
Metadata first. Specify queries with ticker/CIK, filing type, fiscal period, and section. FinanceBench’s shared-store vs single-store gap is a reminder that scope filters are not optional.
Context-first prompt order. Put the evidence before the question to discourage from-memory answers. This ordering shows a dramatic gain in long-context settings. This is a key reason II’s pre-processing prompt set helps. It brings the document data into the context window before running the task which has been shown to improve accuracy.
Verify. Have your prompts append a set of financial tables at the back of any response or report, with all data used and then verify these to source. Alternatively, use dual model approaches to double check. It becomes very obvious where a hallucination appears if 2 models report very different results for a specific calculation or data point from the same prompt.
D. Answering with structure and verification
Schema-first extraction. Consider defining JSON schemas for recurring outputs: the three core statements, segment tables, debt maturity ladders, share count bridges, and SBC roll-forwards.
Span-bound answers with math shown. Every figure carries
(page, section/note, quoted span). If the number is computed, show the formula and cite each input.Verifier pass. Run a second model or rule-based checker over the cited spans to score factual consistency. Add a contradiction scan between MD&A and Notes—if the model cites both with conflicting figures, require a reconciliation or mark Inconsistency/Needs Review.
Enforce Five “hard self-checks” before analysis. This is where the model generates verification questions and answers those, then verifies the answers. If the model finds it failing it looks how to self-correct. e.g.
Revenue recognition timing and contract liability movement (quote policy and movement table).
SBC expense and unrecognized compensation (quote SBC note).
Lease type, discount rate, and short-term expedient (quote leases note).
Debt ladder and any variable-rate exposure (quote debt notes and Item 7A).
Share count bridge and potential dilutives (quote EPS note and equity roll-forward).
This echoes FinanceBench’s emphasis on the tricky categories where models most often overreach.
E. Route work to tools where language is weakest
Prices and time series → data APIs. The finance hallucination study’s stock-price task is unambiguous: don’t ask a generative model to “remember” prices; call a function and cite it.
Govern hallucination risk by smart techniques
The studies agree on two points. First, hallucinations are part of the terrain when models navigate long, complex filings. Even at their best, models will sometimes deliver polished answers that don’t survive a page-level check. Second, they’re manageable and the tools to do so are not exotic.
A single-document scope, hybrid retrieval with proper filters, context-first prompts, tool-calling for prices, and a self-audit that insists on page-linked spans go a very long way. FinanceBench quantifies the upside: closed-book goes nowhere (9% correct), single-document retrieval moves the needle (50%), long context pushes further (~79%), and oracle-style evidence delivery sets the ceiling (~85%). Task-level experiments add the simple rule that saves the most time: never free-generate market data; call a tool and cite it.
At The Inferential Investor, we lean into these rules. Hallucinations won’t vanish, but they can be fenced in with the right document ingest, retrieval discipline, and verification loop. The result is greater confidence and reduced time lost in verification. When every answer carries its page number and every calculation shows its inputs, analysts can spend less time second-guessing and more time making valuable decisions.
The Inferential Investor pre-processing prompt will be available in the prompt library in the near future which will be launched as soon a we achieve the target level of tested, sophisticated investment workflows.
As always,
Inference never stops. Neither should you.
Andy West
The Inferential Investor